Natural language provides an accessible and expressive interface to specify long-term tasks for robotic agents. However, non-experts are likely to specify such tasks with high-level instructions, which abstract over specific robot actions through several layers of abstraction. We propose that key to bridging this gap between language and robot actions over long execution horizons are persistent representations. We propose a persistent spatial semantic representation method, and show how it enables building an agent that performs hierarchical reasoning to effectively execute long-term tasks. We evaluate our approach on the ALFRED benchmark and achieve state-of-the-art results, despite completely avoiding the commonly used step-by-step instructions.
Summary
Task: Follow high-level natural language mobile manipulation instructions in an interactive embodied 3D environment.
Inputs: High-level language, RGB observations.
Outputs: Navigation and interaction actions.
Challenges: Language understanding, long-horizon execution, language grounding, perception, spatial reasoning, navigation.
Key contributions:
- Hierarchical approach consisting of observation model, high-level controller, and low-level controller.
- Spatial-semantic voxel map world representation.
- State-of-the-art results on ALFRED at time of submission using only high-level instructions.
Hierarchical Language-conditioned Spatial Model (HLSM)
Our agent consists of an observation model and two controllers: a high-level controller and a low-level controller. The observation model builds a spatial state representation that captures the cumulative agent knowledge of the world. The state representation is used for high-level long-horizon task planning, and for near-term reasoning, such as object search, navigation, collision avoidance, and manipulation. The following figure summarizes the HLSM model:

Detailed Description
The observation model takes as input an RGB observation, and maintains a semantic voxel map state representation. It first uses pre-trained monocular depth and semantic segmentation models to estimate the depth at each pixel, and to predict for each pixel a distribution over \(C\) semantic object classes. It then projects each pixel to a point cloud, and clusters points into voxels in a global reference frame. Each voxel is represented by a a vector that we compute by max-pooling the semantic distributions of all points within the voxel. We remember the voxel representations for future timesteps, and replace them only when we observe the same voxel again in the future. We also keep track of voxel occupancy. We mark voxels as occupied if they contain any points, and we mark voxels as unoccupied if a ray cast through the voxel centroid terminates behind the voxel.
The high-level controller computes a probability over . A subgoal a tuple that defines a desired future interaction action (i.e. an intermediate goal). It is a tuple \((\texttt{type}, \texttt{argument_class}, \texttt{argument_mask})\) where \(\texttt{type}\) is an interaction action type (e.g., \(\textit{Open}\), \(\textit{Pickup}\)), \(\texttt{argument_class}\) is the semantic class of the interaction object (e.g., \(\textit{Safe}\), \(\textit{CD}\)), and \(\texttt{argument_mask}\) is a 0-1 valued 3D mask identifying the location of the object instance. The inputs to the high-level controller are the language instruction, the current state reprsentation, and the sequence of all previously successfully completed subgoals. During inference, we sample subgoals from the distribution predicted by the high-level controller. Unlike \(\arg\max\), sampling allows the agent to re-try the same or different subgoal incase of a potentially random failure (e.g., if a \(\textit{Mug}\) was not found, try to pick up a \(\textit{Cup}\) instead).
The low-level controller takes as input the subgoal as its goal specification. At every timestep, it maps the state representation and subgoal to an action, until it outputs either a fail or a pass signal. A pass signal means that we consider the subgoal be successfully completed and sample the next subgoal. A fail signal means that subgoal failed, and we should re-sample it again and make another attempt.
Results on ALFRED
Tests results on the leaderboard
Screenshot of the ALFRED leaderboard (as of Nov 5, 2021) for easy reference. For most recent results, visit the official leaderboard page.
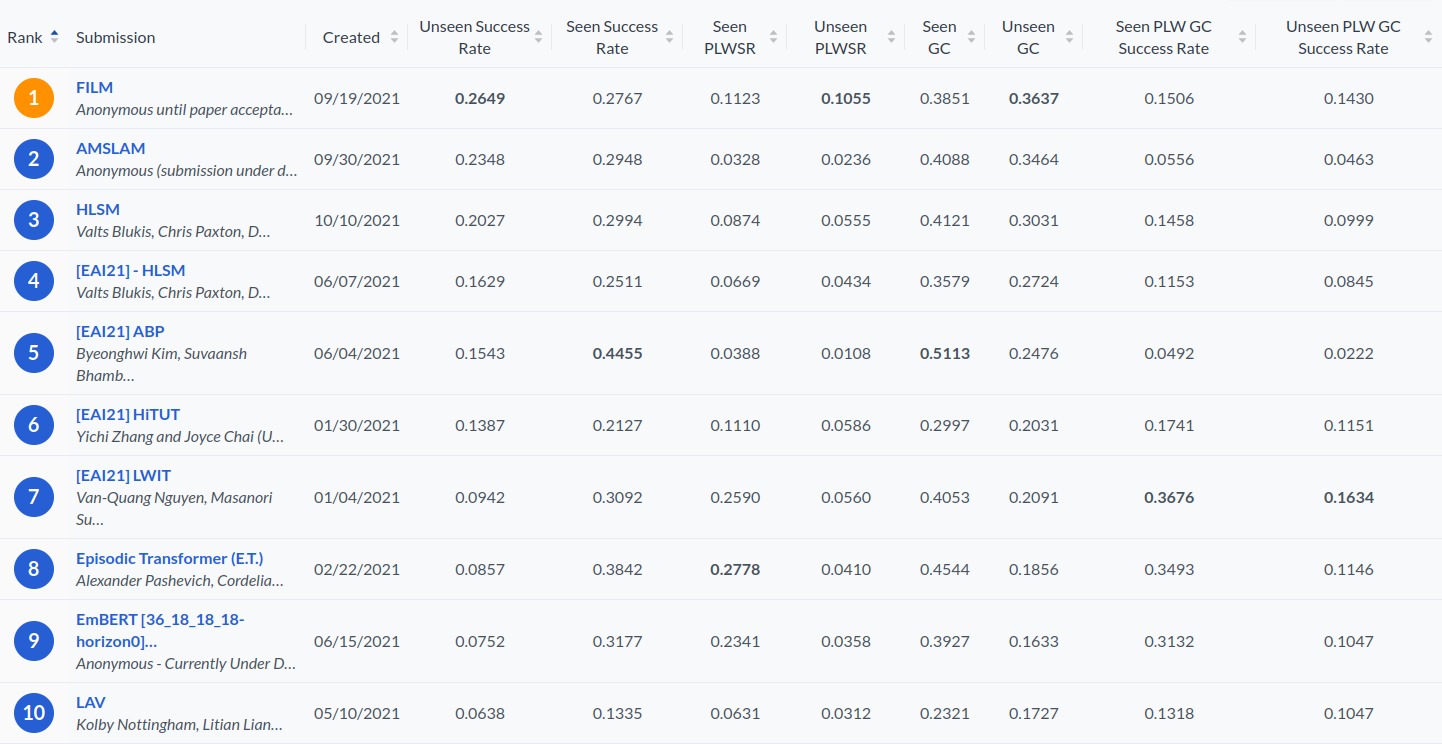
HLSM was the leading method on the leaderboard at the time of submission to CoRL 2021. FILM and AMSLAM are recent methods that have surpassed HLSM on the leaderboard. It’s encouraging that FILM uses a similar hierarchical formulation and a spatial semantic representation to HLSM and builds on this direction, but with a number of changes and improvements that result in higher performance. The main differences include a novel object search and exploration method, and an improved perception pipeline. Another related method that also uses a map representation is MoViLan, though it does not report results on the leaderboard.
Qualitative Examples
Example 1 - Secure two discs in a bedroom safe
Result: Success
Legend:
Top-left: The input RGB image with interaction action masks overlaid during timesteps when the agent performs an interaction action. The interaction action argument mask is computed as the intersection of the two masks in middle-right and bottom-right positions.
Bottom-left: Predicted segmentation and depth used to build the semantic voxel map.
Center: Semantic voxel map. Different colors indicate different classes of objects. The brighter colors represent voxels that are observed in the current timestep. The more washed-out colors represent voxels remembered from previous timesteps. Agent position is represented as a black pillar. The current navigation goal is shown as a red pillar. The 3D argument mask of the current subgoal is shown in bright yellow. These three special voxel classes are not part of the semantc voxel map, but are included here for visualization only. The text overlays show the instruction input, the current subgoal, the current action, and the state of the low-level controller (either exploring or interacting).
Top-right: Value iteration network value function in the birds-eye view. White pixels are the goal location of value 1. Black pixels are obstacles of value -1. Other pixels are free or unobserved space with varying values between 0 and 1.
Middle-right: Mask identifying all pixels that belong to the current subgoal argument class according to the most recent segmentation image.
Bottom-right: The 3D subgoal argument mask projected in the first-person view.
Example 2 - Place the sliced apple on the counter
Result: Failure
Predicted vs Ground-truth Segmentation and Depth
Example 3A - Put a clean bar of soap in a cabinet
Result: Success
This example uses learned monocular and depth models as required by the ALFRED benchmark.
Example 3B (ground truth depth and segmentation) - Put a clean bar of soap in a cabinet
Result: Failure
This example provides ground truth depth and segmentation images at test-time.
Perfect depth and segmentation in Example B results in clear semantic voxel maps. As a result, the agent knows perfectly the location of every observed object, and succeeds in most interaction actions with the first attempt. However, the agent loses track of which sink the soap bar was placed in and toggles the wrong faucet resulting in task failure.
In Example 3A, the semantic voxel map is built from predicted monocular depth and segmentation, and as a result is a more noisy. However, it still facilitates the necessary reasoning to complete the task. In this case, the agent sometimes has to re-try a couple of times before succeeding in each interaction action due to uncertainty about locations of various objects.